|
|
Electronic Warfare Operations |
|
|
Electronic Warfare Operations |
Strategies and Technologies for Modern Drone Defense Security
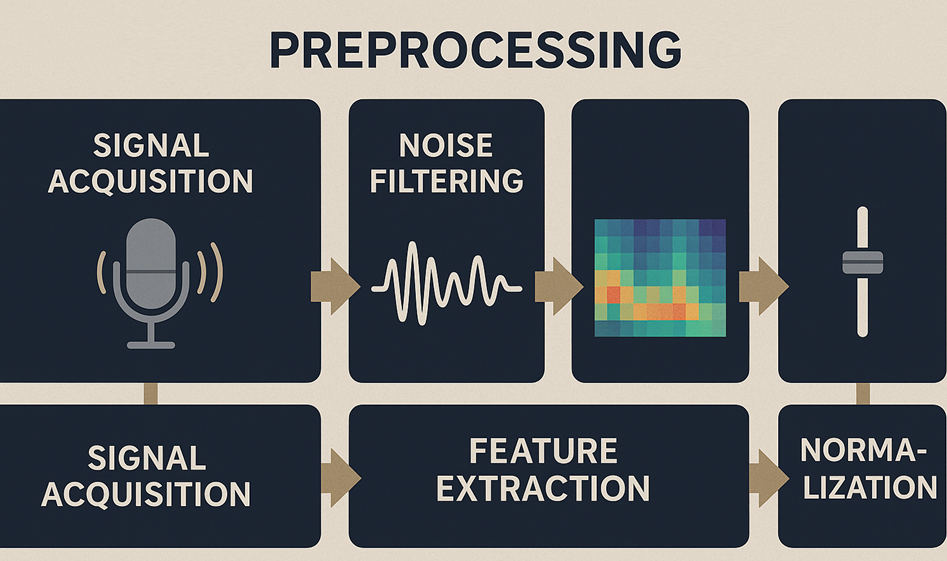
Input: Analog audio from omnidirectional or directional microphones (often MEMS or condenser mics).
Sample Rate: Usually 16 kHz or 44.1 kHz, depending on system bandwidth and drone frequency profile.
Channels: Single or multi-channel (for triangulation/localization).
Removes environmental clutter:
Wind, insects, vehicles, and human speech
Common methods:
Bandpass filtering (e.g., 200 Hz – 7 kHz)
Spectral subtraction
Wiener filters
Adaptive background modeling
The audio stream is split into manageable windows:
Typical length: 1–2 seconds
May overlap (e.g., 50%) to preserve temporal continuity
Segmentation allows real-time inference and continuous scanning
Transforms audio into a time-frequency representation:
✅ Common Features:
| Feature Type | Description |
| MFCC (Mel-Frequency Cepstral Coefficients) | Mimics human hearing—captures timbre |
| Spectrogram | Intensity of frequencies over time (visualized as an image) |
| Chroma features | Tracks harmonic/pitch content |
| Zero-crossing rate | Frequency content via sign changes in waveform |
Example: A 1s clip at 16kHz becomes a 2D array of 13 MFCCs × ~30 frames
Ensures consistency in audio features regardless of mic distance or drone volume:
Min-max scaling
Mean subtraction / variance normalization
Often critical when training across multiple drone models or environments
The result is a standardized input matrix or image (e.g., MFCC or spectrogram) sent to the AI classifier, typically a:
CNN (if using spectrogram images)
RNN or LSTM (if maintaining time-sequence features)
Connect with us for a consultation, site survey, or capability demo.
Contact: ewo.info@ewodronedefense.com